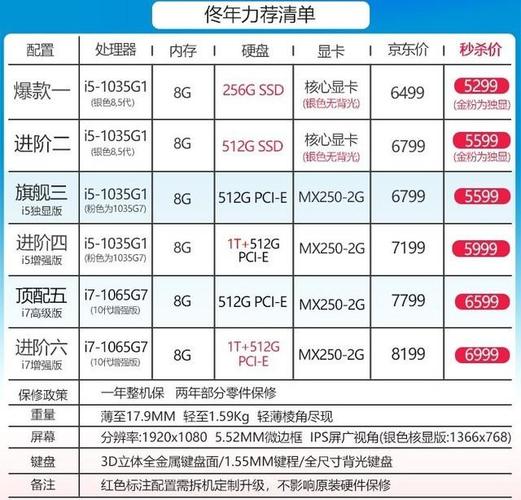
南洋理工团队打造任务数据集和测试基准,提高网页智能体的任务完成能力
近日,通过使用GPT-4v、Gemini-pro等大模型,南洋理工大学实习生张子牛和所在团队发现,目前网页智能体的能力还非常欠缺,尤其是在完成多个子任务混合的任务时。
为了提高智能体在网页上的操作能力,该课题组打造了一个任务数据集并进行基准测试。
在这个数据集的帮助之下,智能体需要处理多模态的网页信息,并通过在不同网页上的操作完成任务,从而更加贴近真实情况之下人们在网页上的操作。
同时,该团队发现智能体存在较大的记忆缺陷,严重影响了多跳问题的准确率,针对此他们提出一种记忆模块,借此改善了上述问题。
总的来说,本次成果将能改进智能体的任务完成能力并为后续工作提供测试基准。
据介绍,本次成果是一系列工作中的其中一个。最初,针对美国卡内基梅隆大学团队打造的单跳单模态测试基准Webarena,张子牛,田淑琳,陈亮宇等人对其进行了复现。
后来,通过仔细分析Webarena的任务能力、以及智能体完成任务的情况,他们发现还有很多值得继续挖掘的内容。
比如,为什么任务不够贴近现实情况?为什么智能体能力比较欠缺等?
通过阅读其他与网页智能体相关的论文。该团队考虑将任务从单模态扩展到多模态。
此前,南洋理工团队打造任务数据集和测试基准,提高网页智能体的任务完成能力当网页智能体在网页上处理信息的时候,通常不会只看文字。为此,他们尝试从一些包含图片的在线网站,比如从一些美术馆的官网中提取图片信息。
但是,由于自身的保护措施,很多网页都不能从其HTML文件中提取图片信息。
后来,他们转而从购物网站和维基百科中提取图片信息,并为网页智能体制作了一些多模态任务。
接着,该团队将任务拓展到多跳任务上,并决定以旅行任务为例来开展研究。随后,他们将智能体在数据集上进行测试。
在视觉信息的处理上,他们也使用了多种方法:比如直接将图片作为prompt提供给智能体,或者先将图片提供给多模态大模型进行处理、再把处理结果合并给智能体等。
期间,他们发现:此前使用的针对任务整体的评价方式,在对多跳任务中并不合适。于是,他们提出了一种针对于多跳任务的新型评价方式。
而在分析智能体的实验结果时,其发现智能体的记忆能力非常欠佳,于是提出了一个记忆增强模块,以用于提高智能体的能力,并针对此做了消融实验。
日前,相关论文以《MMInA:多跳多模态互联网代理基准测试》(MMInA:BenchmarkingMultihopMultimodalInternetAgents)为题发在arXiv。
图|相关论文(来源:arXiv)与此同时,该团队也正在关注网页智能体的最新进展。后续,课题组或打算将整个网页的截屏作为输入来提供给智能体。






则暄
这家伙太懒。。。
- 暂无未发布任何投稿。